Or goodly, depends who you ask!
More evidence is trickling in that LLMs are just like us, humans. (Flawed. Biased. Complex. Interesting.)
How so? Let’s start with this paper (cool title!):
Humans in Humans Out: On GPT Converging Toward Common Sense in both Success and Failure
Philipp Koralus and Vincent Wang-Mascianica find that as certain LLMs become more advanced, they not only improve in producing outputs that align with human common-sense reasoning but also become more prone to making human-like errors. The authors call LLMs common sense approximators.
They start by giving LLMs inference and decision-making problems from the Erotetic Theory of Reason (ETR61 benchmark). The point is to investigate whether models’ outputs align with common-sense judgments, including correct inferences and fallacies, as predicted by ETR, e.g.:

They show that there is quite a bit of alignment between human and LLM responses on these tasks, although humans still do have an advantage when it comes to more complex inference and decision-making scenarios. They also show that more advanced language models are more prone to replicating both the success and failures of human reasoning.
We got common sense down, more or less. What about personality?
Hang Jiang, Xiajie Zhang, Xubo Cao, and Jad Kabbara study whether LLMs, specifically ChatGPT and GPT-4, can embody and convey distinct personality traits based on the Big Five personality model. They check whether LLMs can generate content that aligns with their assigned personality profiles. To do that, they create a bunch of synthetic personas with different personality traits, and then administer a personality test and (embody) to each, as well as have each persona write an essay with a personal story (convey).
These outputs are then assessed using both crowdsourced and algorithmic evaluations:

Results show that LLMs can consistently align their self-reported Big Five scores with their intended personality types, and also show that certain linguistic patterns in their writing correlate with these personalities (!).
Next, let’s see how LLMs do with probability judgements. We know from Kahneman and Tversky that humans suck at those. Do LLMs?
Incoherent Probability Judgments in Large Language Models
(Yes.) Jian-Qiao Zhu and Thomas Griffiths explore whether large language models like GPT and LLaMA can make probability judgments that are consistent, logical, and conform to the principles of probability theory.
They create a set of probabilistic identities, formulated by combining individual probability judgments from a pair of binary events, A and B:

First, this is how human probability judgements look like:
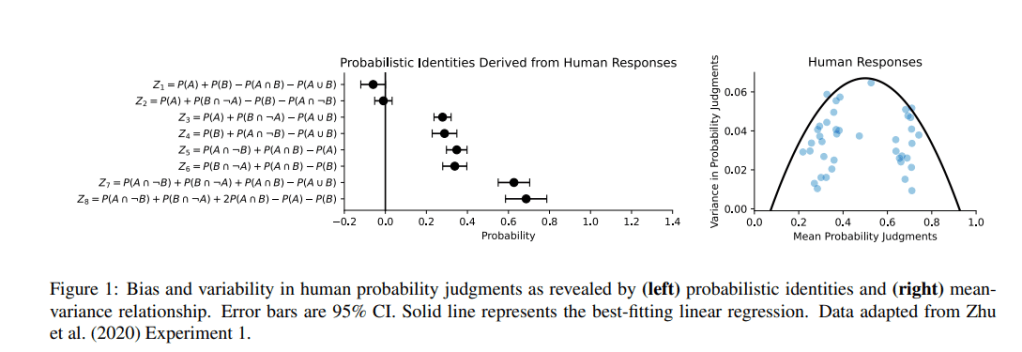
The figure above shows the discrepancy between human probability assessments for different event combinations and the mathematical predictions. The left graph shows mean probabilities calculated from human responses for various probabilistic identities against expected theoretical values (represented by the horizontal line at zero).
This exercise is then repeated with LLMs:

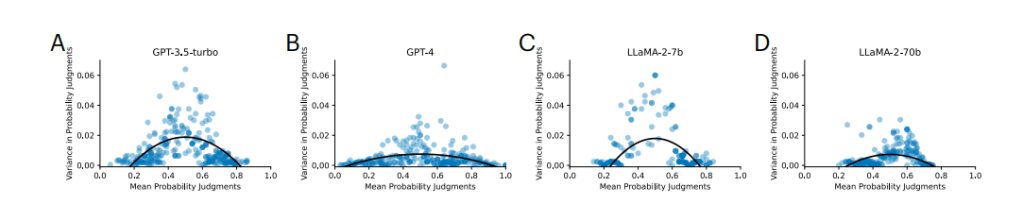
Here, mean probability estimates are closer to the expected theoretical values (0 on the y-axis) in some cases compared to human estimates, but obviously deviate quite a bit. And these deviations are similar to human reasoning patterns shown previously.
The authors argue that these inconsistencies may stem from the models’ autoregressive nature and propose a connection to Bayesian inference, discussing some potential solutions.
So, what are we dealing with here? A funhouse mirror version of ourselves?Whatever it is, it’s fun.

Leave a comment