*This post is co-authored with Benjamin Manning, currently a PhD student at MIT in the IT group at Sloan*
This post is a part of the series aimed at replicating papers featured on Data Colada blog over past summer. The twist is that we’re using the edsl package to run the experiment, and a large language model (LLM) to generate survey participants.
In this post we replicate the now-retracted study by Gino, Kouchaki, & Casciaro (2020), “Why Connect? Moral Consequences of Networking with a Promotion or Prevention Focus“. The goal of the original paper was to investigate the hypothesis that different mindsets influence people’s feelings towards networking. The authors explored two mindsets: “promotion focus,” where individuals think about their goals and aspirations, and “prevention focus,” where the emphasis is on duties and obligations.
The study involved 599 participants recruited through Amazon’s MTurk who were randomly assigned to one of three groups (promotion, prevention, and control). Each group completed a writing task designed to induce a specific mindset: writing about a hope or aspiration for the promotion-focused group, about a duty or obligation for the prevention-focused group, or about usual evening activities for the control group.
After the task, participants were asked to imagine themselves at a networking event and subsequently rate their feelings of “moral impurity” towards networking on a 7-point scale (with 1 indicating no negative feelings and 7 indicating a strong sense of moral impurity). Additionally, participants had to list 5-6 words describing their feelings about the event (e.g., “I”, “want”, “to”, “go”, “home”).
Now, prepare to be shocked – or not. The results of original paper find that, as predicted, participants felt more impure about the networking event in the prevention condition than in the promotion condition.
Who would have thought. Well, not Data Colada – see their original post. Those 5-6 descriptive words per participant really ruined everything for the authors, sabotaging those potential book deals.
Ah, these business school publications and their mass market renditions…

It could have really been something. “Schmooze or Lose: The Virtuous Art of Networking Without the Guilt”? Would totally buy.
Back to our exercise. We replicate the Study 3a by generating a population of agents with characteristics identical to those in the study.1 This is done using the Agent function from the edsl package. The below is a simplistic example, but one can get really specific when generating an agent (think age, gender, profession, education, preferences, risk appetite, etc.):
from edsl.agents import Agent
persona = "You are a winter enthusiast."
agent = Agent(traits={"persona":persona})We then offer each generated agent the original scenario presented in the paper, together with a randomly assigned treatment, and collect the results. The package has a way of setting up multiple survey questions, and then running scenarios based on varying conditions.
So what does our synthetic replication produce?
Below is the plot from the original study (+ Data Colada notes). It shows the average moral impurity rating for every participant:

And here is the same plot showing the average moral impurity rating for every participant in the study, based on the synthetic answers we get:
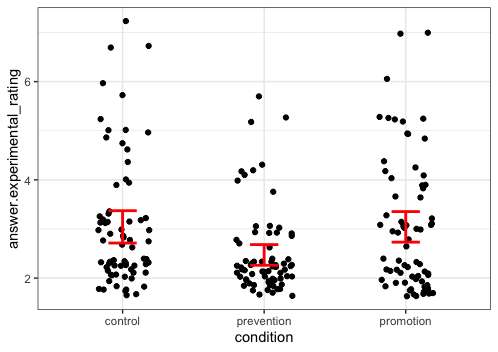
In the original study prevention group was predicted to have high ratings while promotion group should have had low ratings – as you can see, the situation is reversed. (Just like the Data Colada folks show once they remove suspicious observations from the study.)
And there you have it. More to come!
- Interestingly, the researchers in the original study treat their MTurk participants sort of like synthetic agents as well. The average age of participants in the study is 36.9, while they are asked to pretend to be new college graduates. ↩︎

Leave a comment